IoT Thing Availability at Scale in PostNL
PostNL is following the ambition to become the leading postal tech company and our serverless journey on AWS continues in full speed. In this blog post, I would like to give you some information about the IoT-Platform of PostNL and how we evolve our internal services to create the optimum solutions for the problem at hand.
As PostNL, we remain dedicated to be your favorite deliverer in the Benelux area which requires a significant technology infrastructure. Our colleagues in the field are working hard to deliver your packages to your doorstep as soon as possible. The engineering community in PostNL works together with our colleagues on the field and see how we can enable them to achieve our ambition.
The IoT-Platform of PostNL is in a key position to enable data driven decisions because “IoT-Platform connects the physical world to the digital world!” and relay the events that are happening on the field objectively and reliably to the business. Our platform handles more than one billion events per day, ingesting all the traffic from tracked PostNL assets and processing them in record speed to enable close to real-time business events. Using the data streaming from the IoT-Platform, other teams in PostNL can make decisions based on actual data, optimize asset utilization, and create many more use cases.
The Problem
One of the important events in IoT domain is the availability of the edge devices. A common term for this detection is a heartbeat. In the asset tracking solution of the IoT-Platform, a device corresponds to a beacon which has some sensors in it. The beacon can advertise the sensor telemetry through gateways and the data ends up in the IoT-Platform for further processing.
In our case, any message received from a beacon can be considered as a heartbeat. Through heartbeat of the beacons IoT-Platform can evaluate whether a beacon is active or not. When beacons are not active or when they are not sending data to the IoT-Platform for a long time, we might decide to take an action. For example we can create an alert to check the battery of the beacon or log the last known GPS point of the asset so that we can find it in the logistic network and bring it under maintenance. There are more intricate use cases that rely on beacon availability, but let’s skip those for now to keep things simple.
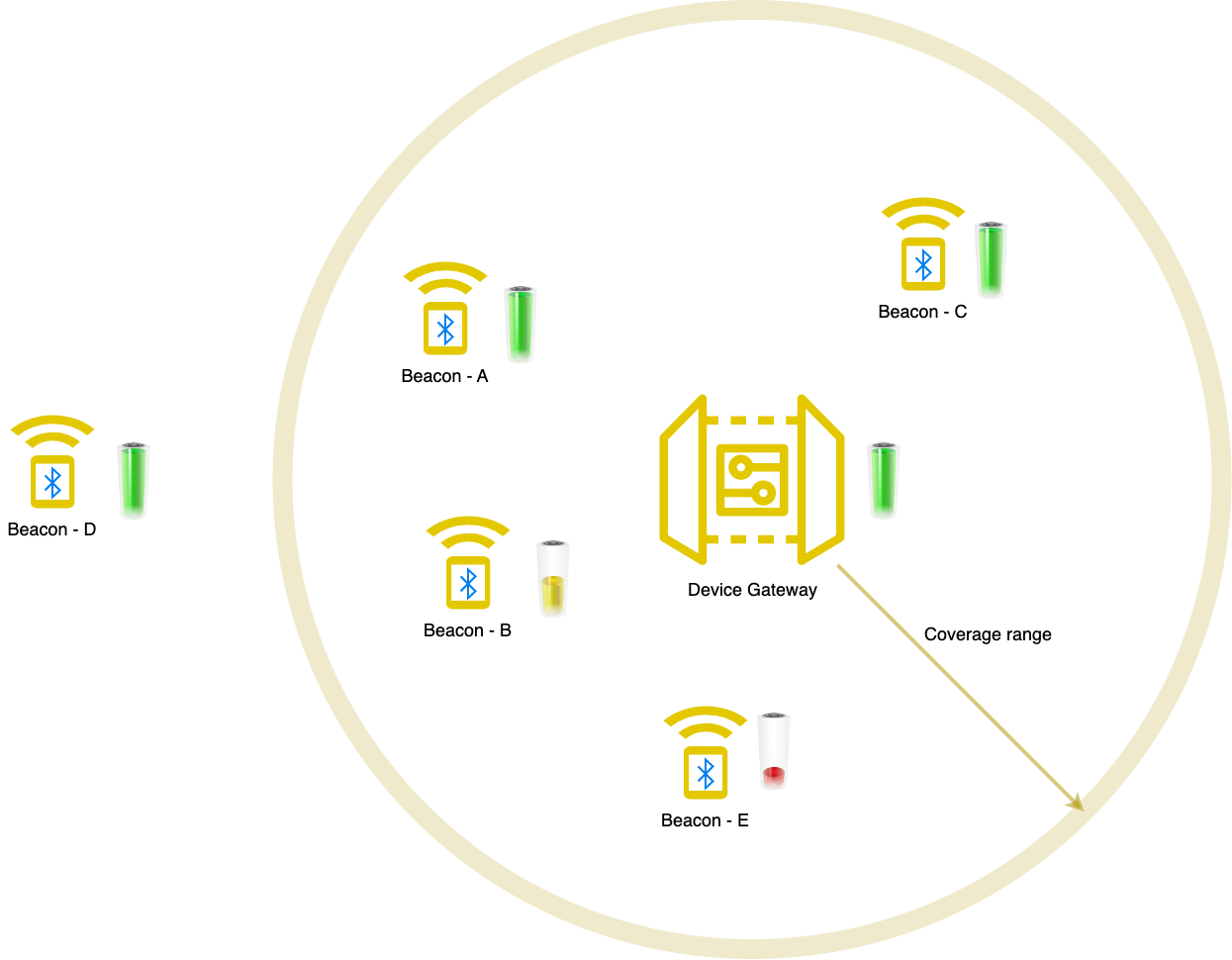
Now that we have established the need for heartbeat messages, let’s explore possible solutions. The first question to consider in these situations is: “Does AWS offer a built-in service?” And the good news is, yes! AWS has a built in service for this purpose, AWS IoT Events, which supports device heartbeat. This solution works great out of the box, unless you need to scale it to a high number of assets. The IoT-Platform tracks more than 300.000 assets throughout the Benelux area. If you check the pricing of AWS IoT Events, it is obvious that the costs would go through the roof for our scale.
Initial Solution
Availability events (device heartbeat) was one of the first cases where we needed a kind of state machine, that is aware of previous detection(s) from an asset which can also act on current detection. (When I mention state machines, AWS Step Functions could be evaluated as one of the first solutions on AWS. Unfortunately, with our scale AWS Step Functions have some limitations, but that’s a topic for another blog post. ☺️) Here are the simplified requirements:
- When a beacon connects to the IoT-Platform for the first time, we should generate an AVAILABLE event.
- As long as we keep receiving detections from the same beacon, we should not send any other event.
- When we do not receive any detections from the same beacon for a certain amount of time, we should generate an UNAVAILABLE event and mark that beacon is not accessible.
- Repeat for each beacon.
If you consider the requirements above closely, it looks like a mechanism which is used in every large software system: a cache with time-to-live. We just need to generate events when writing to the cache and evicting from the cache.
So the next question was to find a solution that can scale good enough until similar patterns emerge (where we would need more state machines) and the costs of it should be acceptable. After considering multiple options, we ended up with this basic setup:
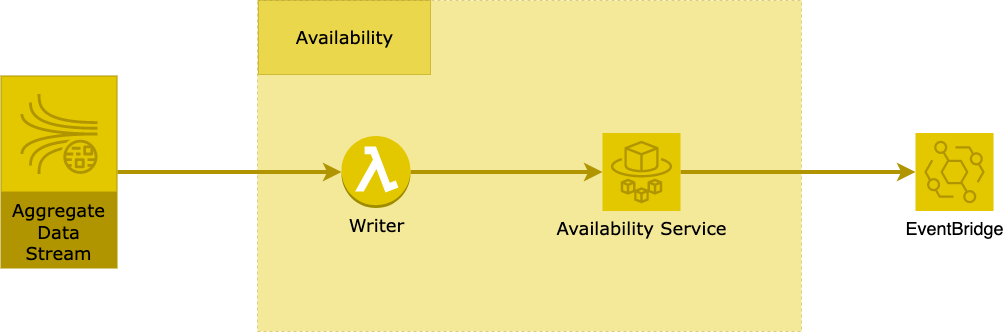
On the left side, you see the aggregated data stream where we have the beacon detections. In the “Availability Service”, a Lambda that listens to the detections coming from the beacons. The Lambda writes data to a Fargate container which has an in-memory cache implementation. The container generates events when writing records to the in-memory cache (AKA: Available Event) and evicting records from the cache (AKA: Unavailable Event). As you can see from the output of the “Availability Service” the generated events are sent out to the EventBridge for further processing.
Pros
- Simple enough.
- Costs less than 10$ per month to run.
- Scales well vertically. We have a lot of room to grow until a replacement will be necessary.
Cons
- More code to support in-memory cache! Every line of code is a liability and requires maintenance.
- We need to think about the persistence of in-memory cache especially during start-up, tear-down of the container to prevent data loss.
- Cannot scale horizontally to multiple containers.
Evolution of the Initial Solution
As I mentioned in the previous paragraphs, the initial solution was just good enough while we can observe the platform for similar patterns. If we wouldn’t need to scale up, the initial solution will work reliably for a long time with a low cost.
However, in a dynamic environment like the PostNL’s logistics infrastructure, no solution remains static for long. As the IoT-Platform grew, the number of assets that we track increased and we needed more types of events that required state machines. With different types of telemetry processing, we needed to check for threshold breaches and generate events based on the changes. For example, position telemetry required a cache to evaluate movement where we needed to compare the current position with the previous position. For accelerometer, we needed to compare the current value with the previous value so that we can generate a breach event based on a threshold. The accelerometer event type was the third strike for us which showed similar patterns. At this moment, we already had enough experience on how to deal with these events and we have seen various requirements that we needed to support. The collected information was invaluable for us, because now we can design the new solution to support all past and (most) future requirements as we have seen much or less all the possibilities with this kind of event processing.
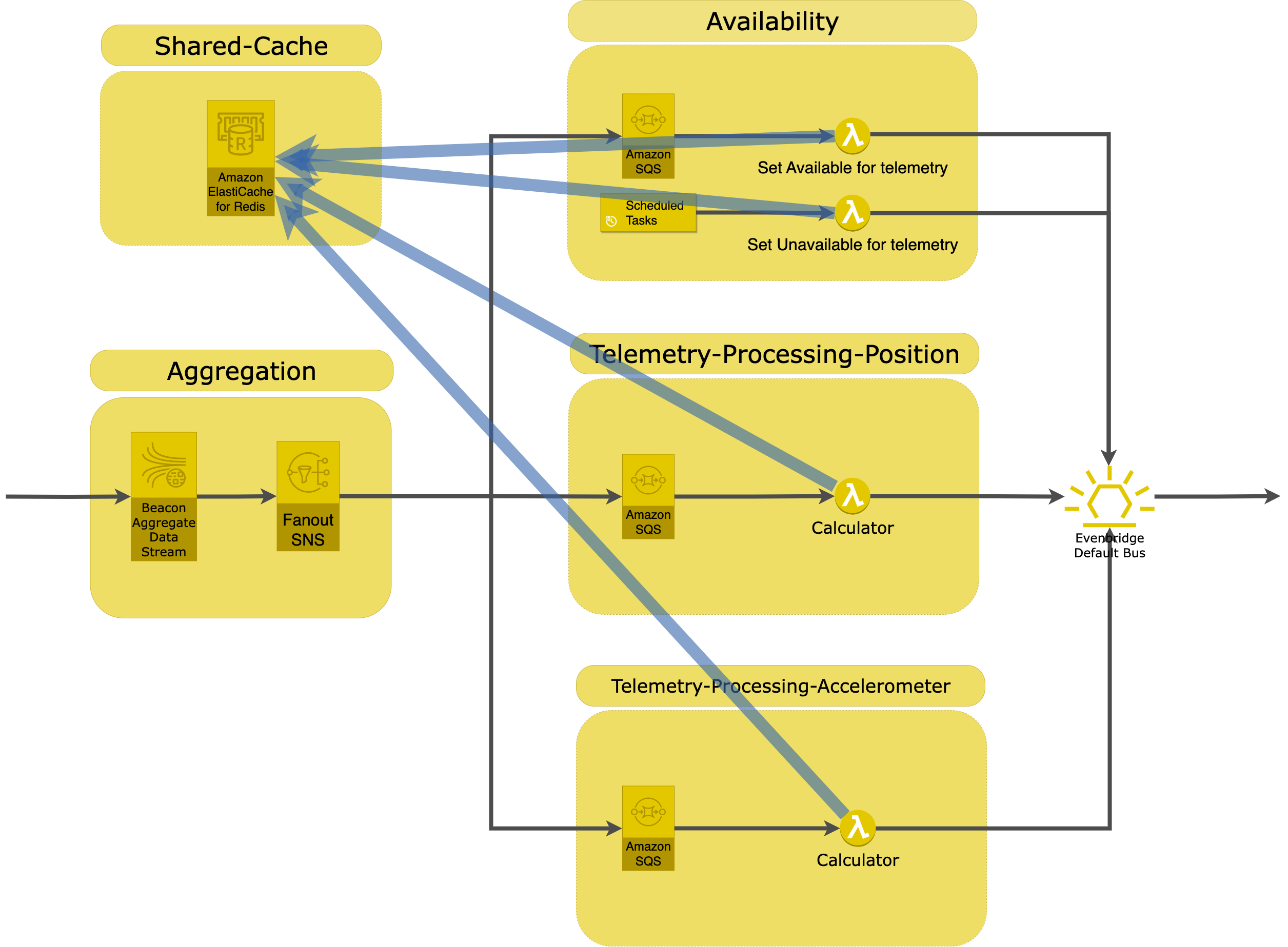
The new design of the availability service has exchanged the in-memory cache with AWS ElastiCache for Redis. AWS ElastiCache for Redis is configured for multiple availability zones for high resilience. We used multiple instances to prevent bottlenecks and support automatic fail-over.
As you can see, there are now multiple services that require a cache. The lambdas are stateless as expected, but they can get information about the previous detections from the Redis cluster and compare it with the current detection. The code for similar functionality is decreased significantly which increases maintainability. By selecting the correct data types in Redis that fit the problem, we enabled high throughput for all services.
Conclusions
In a competitive market like logistics and e-commerce, it is important to be lean and agile. This story illustrates how we achieved a fast time to market based on building exactly what we needed. As patterns started to emerge, we evolved and optimized our architecture based on new insights.
As a concrete example, you can argue that we could have started with the Redis cluster right of the bat and you would have a point. For the sake of discussion, let’s ignore the cost implication of a Redis cluster, because running a cluster on AWS is costly and it is a significant commitment for small projects or early stages of a large project.
If we started with a Redis implementation right from the start, we would have missed a lot of optimization points that came from observing the system and looking for patterns. Choosing the right configuration for your Redis and the correct data types is not a trivial task. You need to have a lot of insight about how the data will be used. Trying to predict the future with limited knowledge leads to premature optimization. Premature optimization will require rework to fix and you would risk introducing downtime to many services when you make changes to the cache.
What I am trying to say is that do not rush for decisions until you see enough patterns in your system. A good enough solution allows you to collect information and then you can select the best solution that meets all requirements.
During long years of development, your systems will definitely need to evolve. With time and more consumers, requirements and the context of your workload will change, and new business features will be introduced. Therefore, when designing your services, it is crucial to consider how you can effectively support and facilitate the necessary evolution.
Embrace evolution, thrive with adaptability!
Thank you for reading our story. I hope you enjoyed this blog post. Happy coding!