
At PostNL, our ambition to become the leading postal tech company continues at full speed. As we work towards being the favorite deliverer in the Benelux area, we must ensure our technology infrastructure is robust, scalable, and adaptable. As PostNL, we have embraced working with AWS and serverless to achieve our ambitions. In this blog post, I would like to you give an overview of a system architecture style called “Serverless Modular Monolith”. We adopted this architecture style for its multiple benefits, and it has worked well for various types and scales of applications.
This post will be a two part series:
- Part 1: We will explore the various serverless applications at PostNL, including planning, operation execution monitoring, and enabler applications, each with unique requirements. We will discuss different architectural styles: monolithic, fully serverless, and serverless microservices, highlighting their pros and cons. Finally, we will introduce the concept of “Serverless Modular Monoliths”.
- Part 2: We will discuss how we are building “Serverless Modular Monoliths” and the practical benefits they offer. Finally, we will conclude the series with a recap.
The Challenge of Delivering at Scale
To meet the ever-growing demands of parcel delivery, we need a sophisticated technology stack that can handle everything from planning to real-time operations. Our engineering teams work hand in hand with our colleagues in the field, ensuring that every parcel reaches its destination as efficiently as possible. But this level of efficiency doesn’t happen by accident, it requires a well-planned and executed system architecture.
Different Applications, Different Needs
To deliver your parcels as quickly and as efficiently as possible, a lot of preparation, planning, and operational execution monitoring is necessary. As a Principal Software Engineer, I work closely with one of these departments, where we manage different types of applications. We can group them into three main categories. Let me give you a high-level overview of these applications:
Planning Applications: These applications focus on the planning aspect of our logistics. PostNL has many sorting centers, and when planning, many characteristics of each sorting center need to be taken into account.From parcels perspective, sorting centers have different parcel sorting, holding, and processing capacities. From the staff perspective, the sorting centers have different shifts, working hours, and the capacity of colleagues who work there. To utilize all our resources efficiently, we use machine learning algorithms that are designed and industrialized to answer specific questions during the planning phase. Planning applications have low scaling requirements, as they do not have many concurrent users executing simulations at the same time. However, they require significant compute power because they collect and process huge amounts of data to feed and run our simulations. Using the results of these simulations, we can select the optimum planning for our sorting centers.
Operation Execution Monitoring Applications: These applications handle real-time data, ensuring that daily operations run smoothly. They are designed to be responsive to the constant flow of information coming in from the field. This includes tracking the number of parcels arriving at sorting centers and monitoring for any operational anomalies. As these applications must process large amounts of data in near real-time, they have medium compute and scaling needs, balancing latency and cost with the ability to scale up as necessary.
Enabler and Integration Applications: Systems like our IoT-Platform fall into this category. They process massive amounts of data, with scaling needs that are through the roof. At the time of writing this blog post, our IoT-Platform processes close to 3 billion events daily, tracking assets across the Benelux area. These applications either generate raw data or enhance and facilitate its flow, ensuring that consumer applications can effectively process the information. So performance and scalability are of the sole foundation of these kind of applications.
Some of these applications are using a specific type of systems architecture called “Serverless Modular Monolith” that exploits the scalability and simplicity of serverless together with a modular monolith approach, which makes deployments and maintenance easier. As you can see from the above overview, “Serverless Modular Monolith” has been a good fit for various types of applications in PostNL, even though there are different compute and scaling needs per application. This is mainly due to the underlying concepts in “Serverless Modular Monolith” because it can adapt and evolve depending on the needs of the application. We will mention these concepts in the later sections of this series. Before diving into details, let’s explore why we chose “Serverless Modular Monolith” from evolution perspective.
The Evolution of System Architecture
When designing a system architecture, the choices we make have far-reaching implications. Traditional monolithic architectures offer simplicity but struggle with scalability and reliability. On the other hand, microservices provide flexibility and scalability at the cost of increased complexity. So, where does the “Serverless Modular Monolith” fit in?
As PostNL, we prefer to build AWS Serverless applications. However, we still need to choose an architectural style that will allow us to build and evolve our system with the needs of the business.
Since we are working with Serverless, let’s have a look at our options in architecture with some examples.
Monolithic Stack
This one is a bit extreme, but if you would like to operate a simple systems architecture, it is possible with AWS serverless. You can achieve this by adding all your functionality in a single ECS Fargate container hence making a monolithic systems architecture where all necessary functionality resides together.
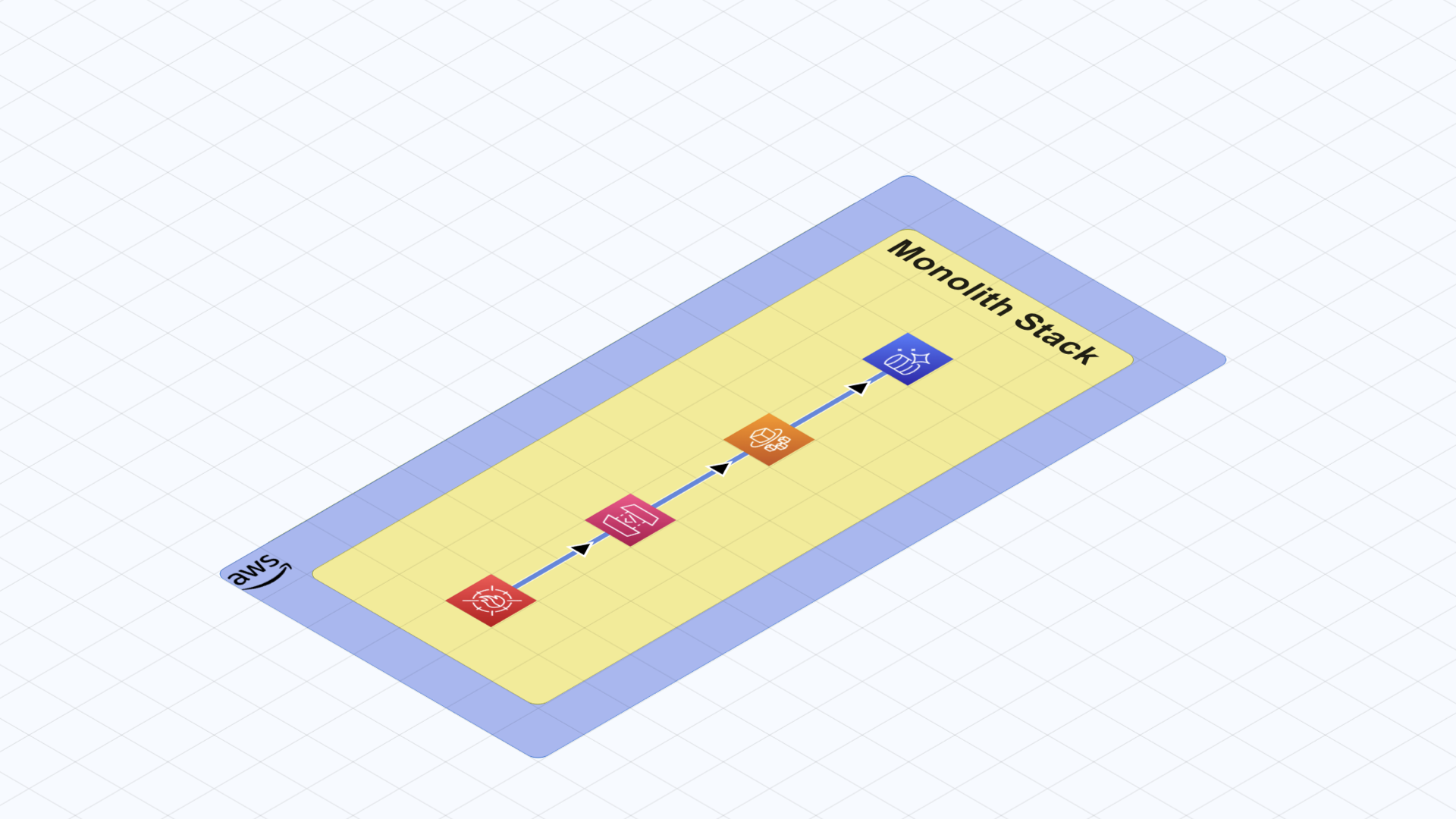
With a monolithic system architecture, the success of the project heavily depends on your software architecture. This is mainly because your system architecture is a single unit. There is a significant risk that if you do not strictly follow development principles and best practices, your software architecture could become a big ball of mud. On the other hand, if we make the right choices with this architecture, we can actually keep it running for a long period of development.

Fully Serverless Stack
The next option is to go fully serverless without following any architectural style, adding components as new features come along. There are many services on AWS that help integration among different services like SNS, SQS, EventBridge and others. These integration services help with isolation.
But consider this for a moment. If you keep blindly adding more and more serverless components, how is this any different than a big ball of mud? At some point, it will become extremely difficult to reason with the overall application due to high number of connections and dependencies.
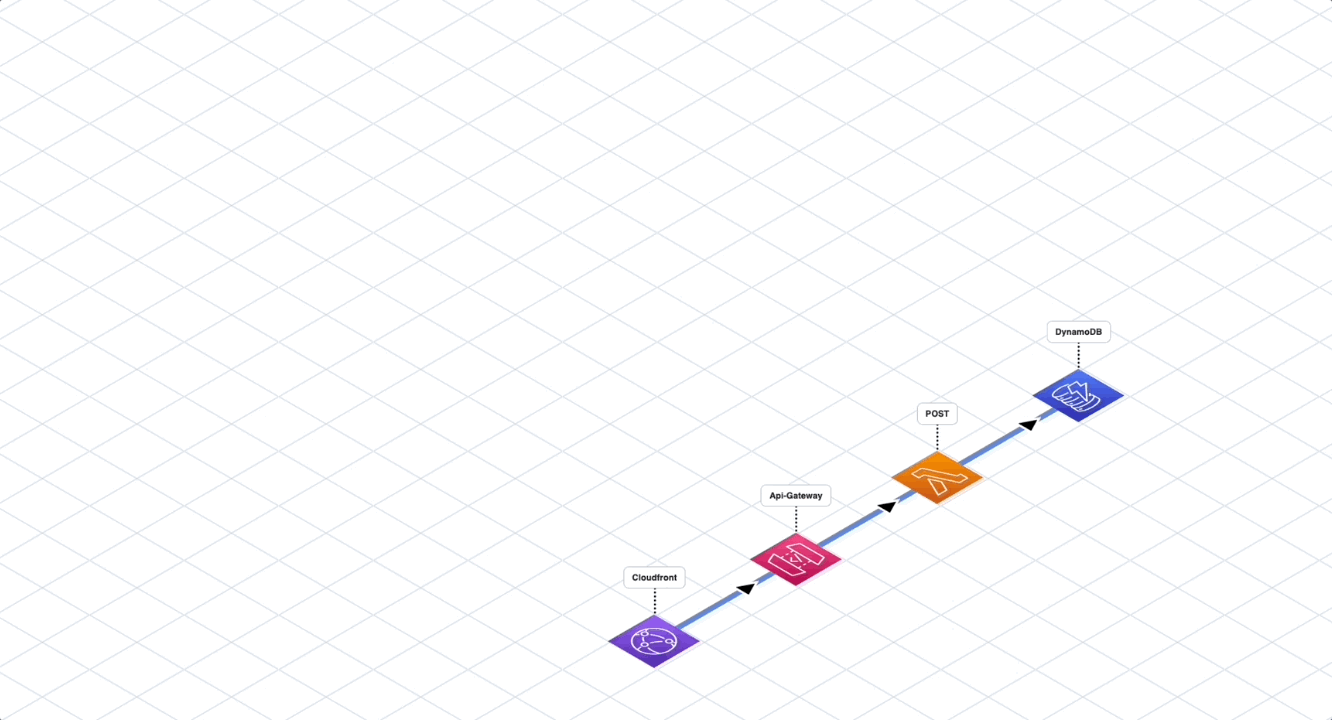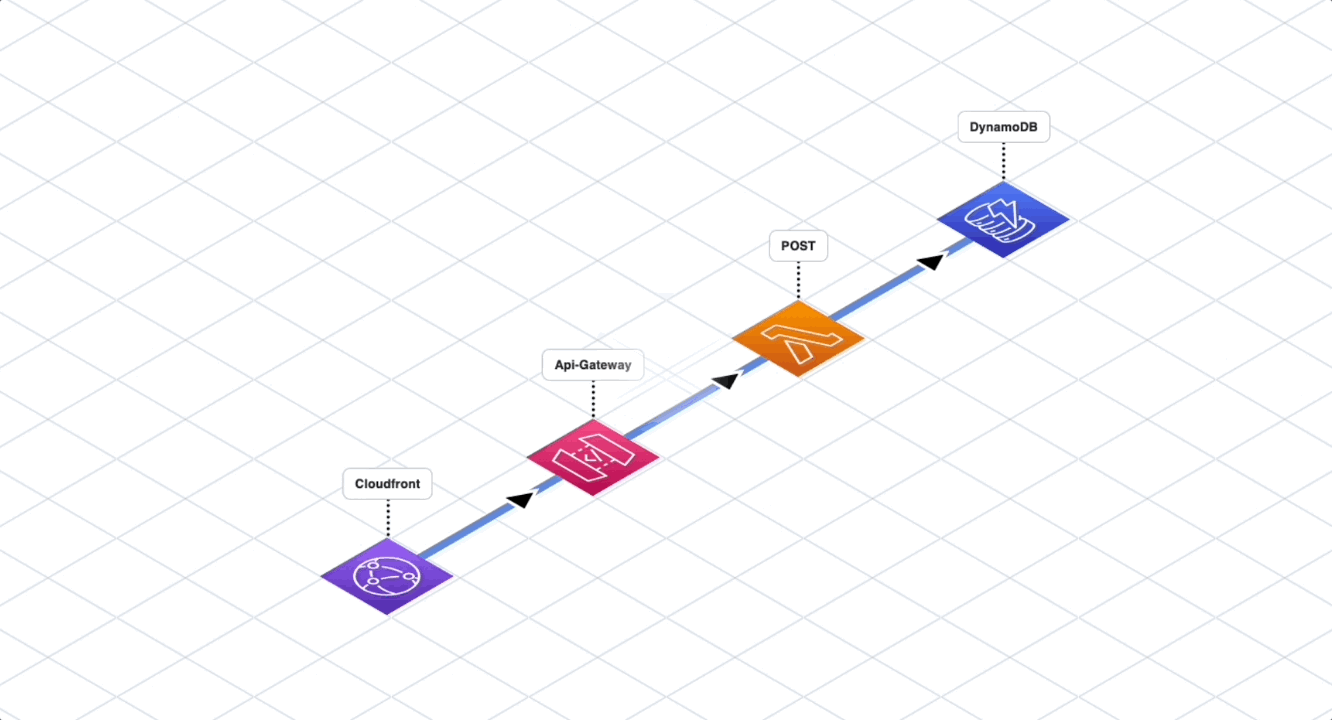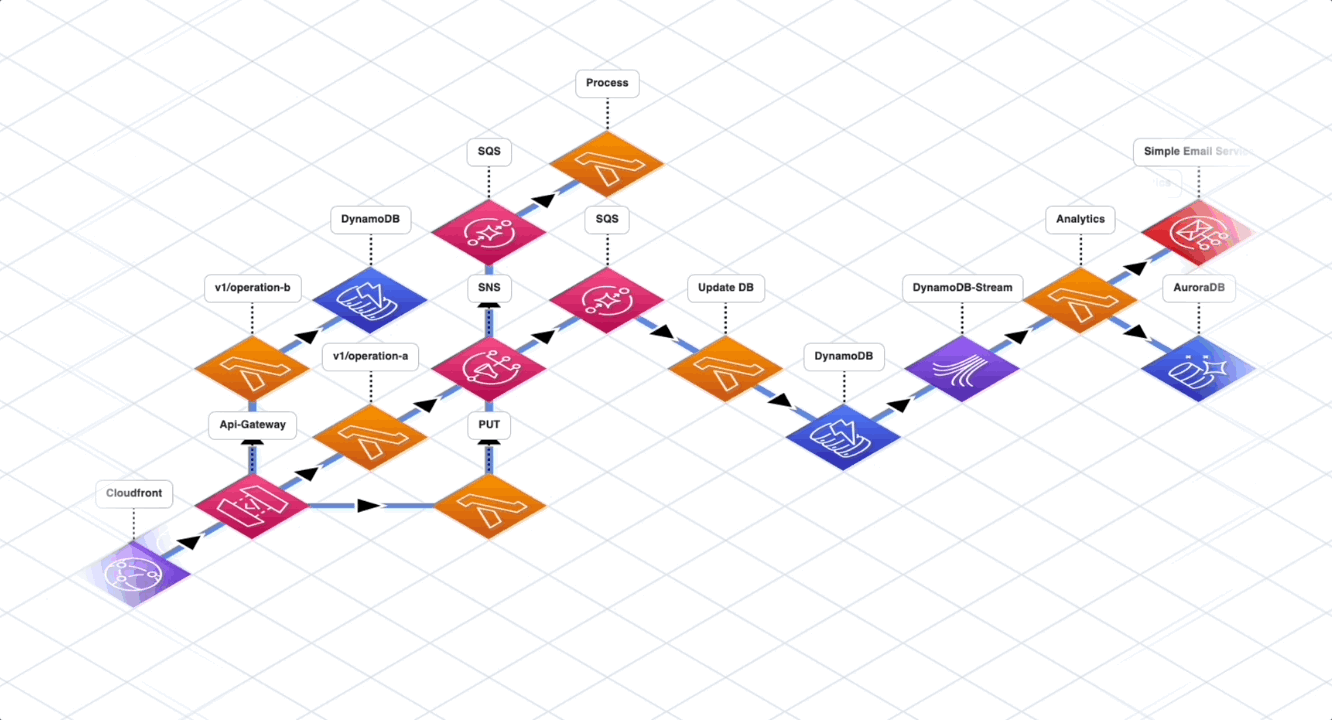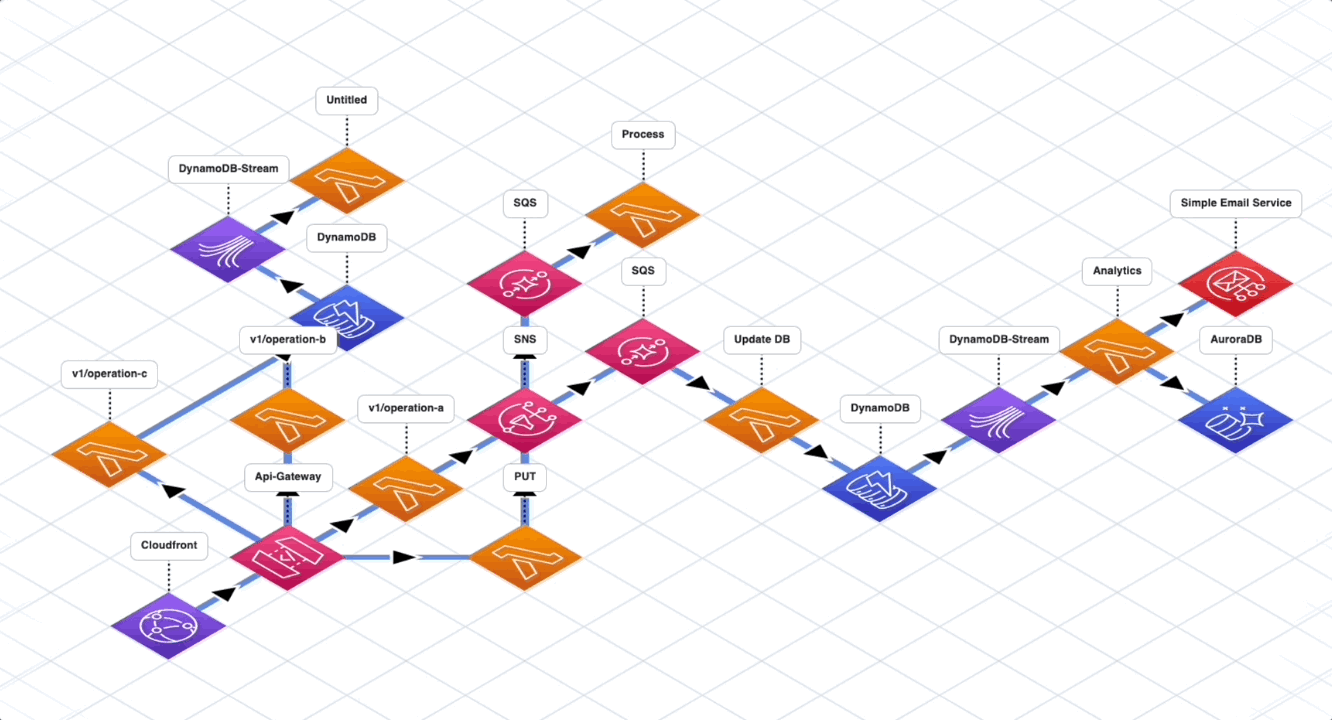
Serverless Microservices
This option is probably where you should end up if your system keeps evolving. As you can see, there are 3 AWS CDK applications in this system. Their operational borders are clearly defined and they interact only through integration services like EventBridge in this example.
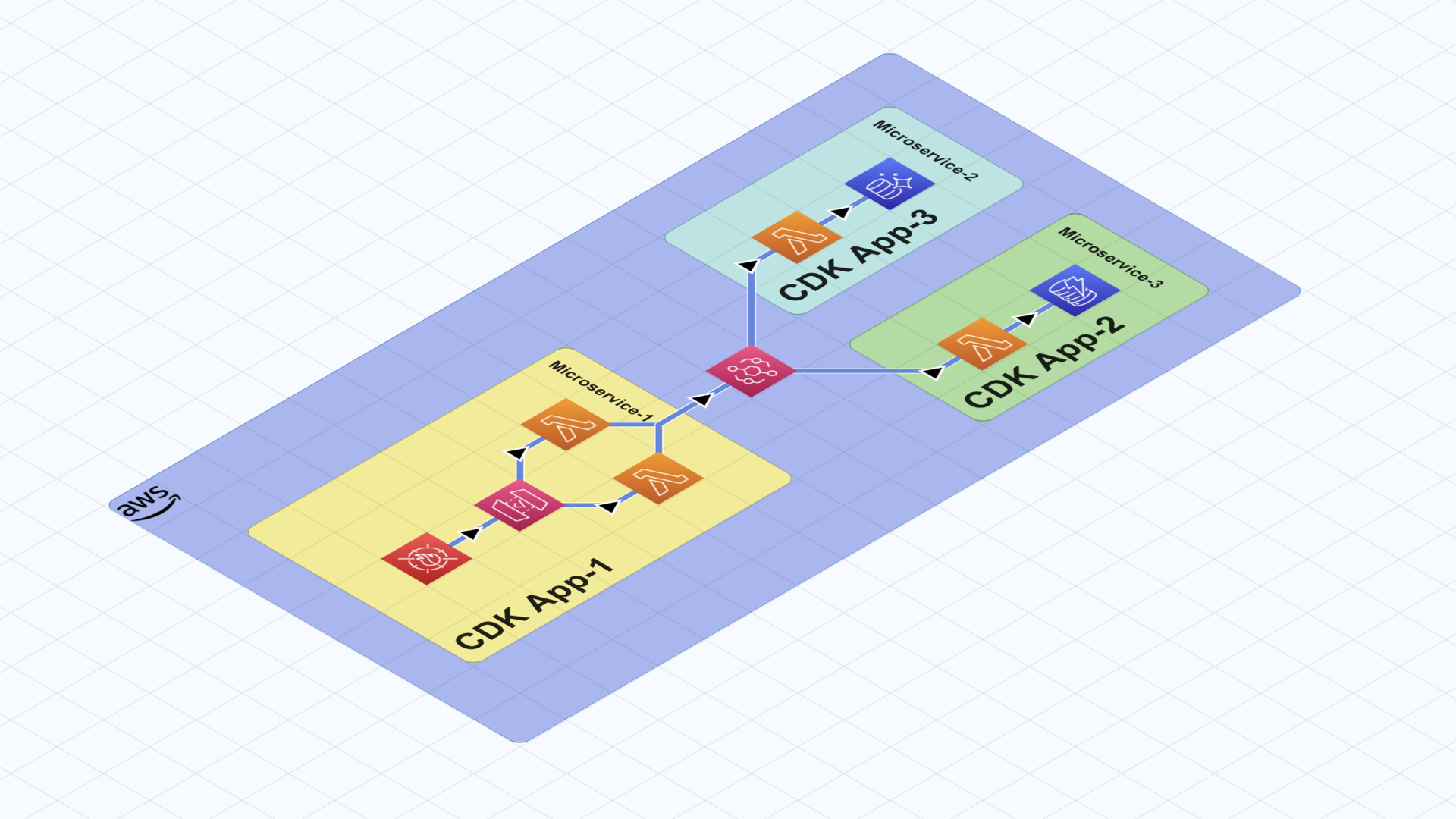
However, if you start with this implementation immediately, you might be skipping a step in the evolution of your system and that decision might cause additional work and effort for your team where it could have been avoided.
Why?
First of all, getting the bounded contexts of such microservices right is tough. The balance between functional cohesion and deployment size (granularity) of the microservices defines their capability to evolve. This is also referred as “Architectural Quantum” in the book “Building Evolutionary Architectures”. What I mean by that is, if you do not get the bounded contexts right and you split the services that should have been deployed together (low granularity), you would need to deal with difficult problems like “distributed transactions”, and you will notice that you are not fully reaping the benefits of using microservices. When you need to make a change in one microservice, you will notice that you also need to make a change in the other to keep them working together. Getting the bounded contexts (granularity) right on the first try in a new domain with microservices is close to impossible unless you have done it a few times before.
There is also another aspect.
You are adding significant work for deployment orchestration (dependency management between microservices) right at the beginning. Now you have to start thinking about deployment strategies right from the start.
Consider the following:
While searching for the borders of the bounded contexts, you will need a number of deployments with multiple microservices. In order to prevent downtime, you will need to start thinking about deployment strategies like blue/green or canary deployments while making changes to the microservices. Sometimes sequential deployments will be necessary and you will need to plan ahead.
All these require additional complexity to manage where some of them could have been avoided especially at the beginning of a new project.
Serverless Modular Monolith
Isn’t there a better way to experiment with the bounded contexts from a single AWS CDK App? That would make deployment orchestration so much easier and we can move resources around until we are confident with the bounded context. We know from experience that AWS CDK can handle extremely complex deployments.
The answer is “Yes!”, there is a way to achieve that. With “Serverless Modular Monoliths”. In Part 2 of this series, we’ll dive deeper into the specifics of how we build “Serverless Modular Monoliths” in PostNL.
Stay tuned for a closer look. Until then, happy coding!