
In Part 1, we explored the various applications at PostNL, including planning, operation execution monitoring, and enabler applications, each with unique requirements. We discussed different architectural styles: Monolithic, fully serverless, and serverless microservices, highlighting their pros and cons. At the end of part one, we introduced the concept of the “Serverless Modular Monolith”, setting the stage for a deeper dive in part two. In this part, we will discuss how we are building such systems and the practical benefits they offer. Without further ado, let’s start!
Serverless Modular Monolith
The first question is “How do we build our “Serverless Modular Monolith” systems?”
“Serverless Modular Monolith” name might not make any sense because how can a system be serverless and a monolith at the same time? It requires some additional context. Please let me explain.
It is easier to explain the concept through an example, so let’s consider the following system:
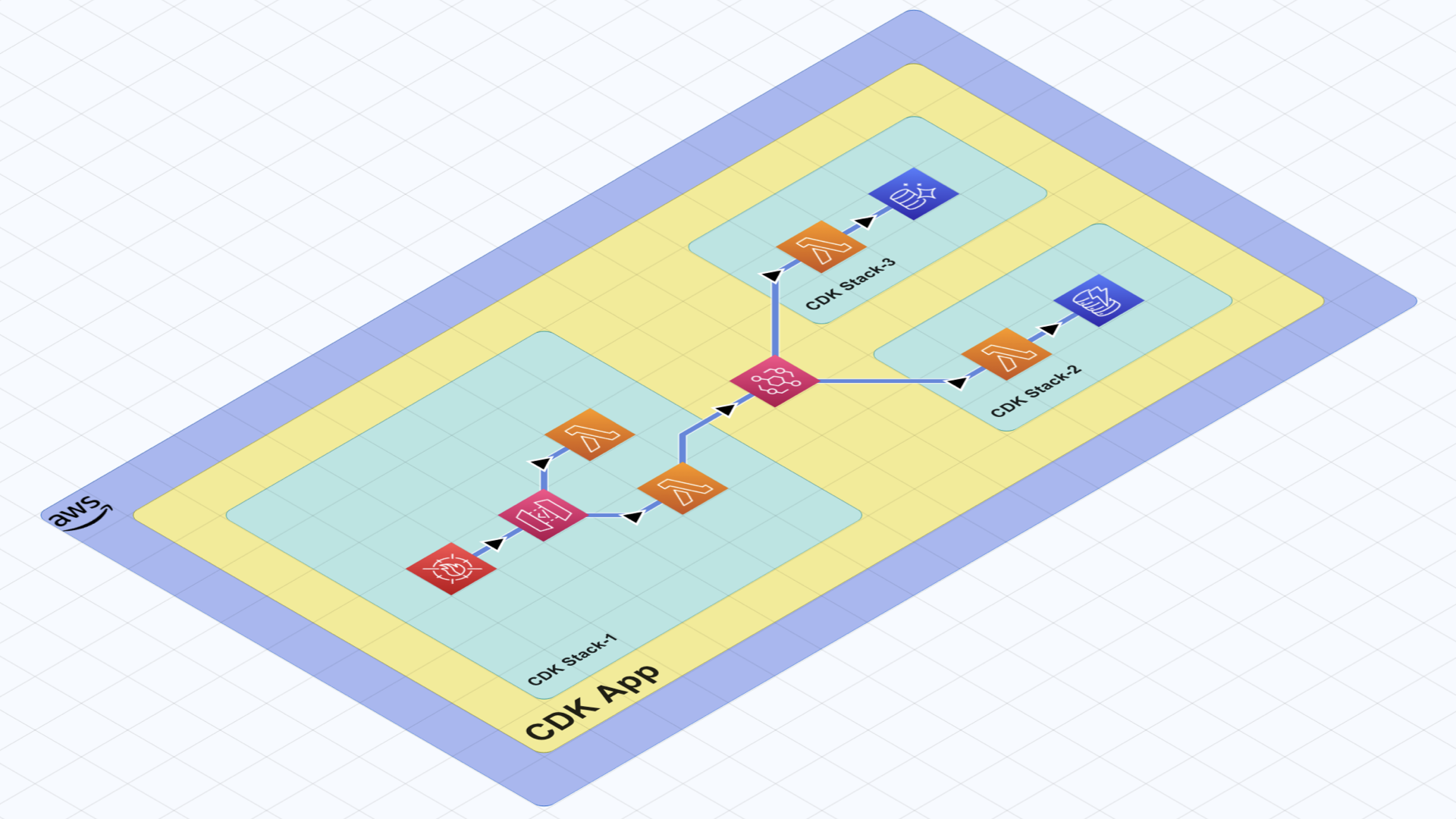
In this example system, we deploy a single AWS CDK Application which resides in its own GitHub repository.
The main CDK project that is shown in the diagram contains only the scaffolding and orchestration of inner modules. There is no business logic in this repository. The business logic that defines the functionalities of the application is handled by the inner modules, which we will cover later. In essence, the overall system is a single CDK application, hence the “monolith” in the name.
Each module within the main CDK application is a dependency and is deployed as a nested Cloudformation stack. The connection between modules and the orchestration of data flow is managed by this CDK application which is where the “modular” aspect comes into play. Note that the entire application is deployed at the same time as a single unit, so it will either succeed or fail altogether.
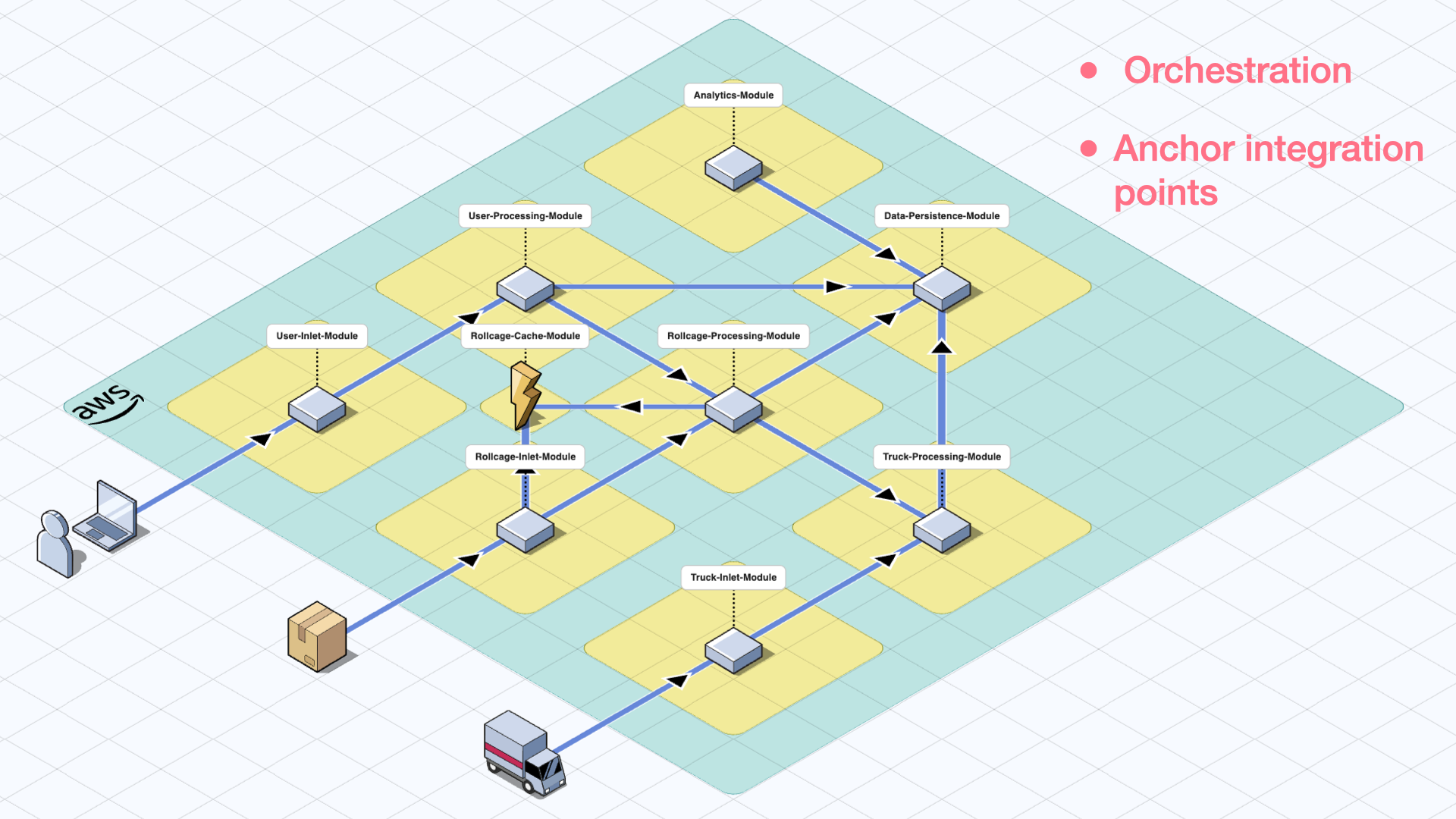
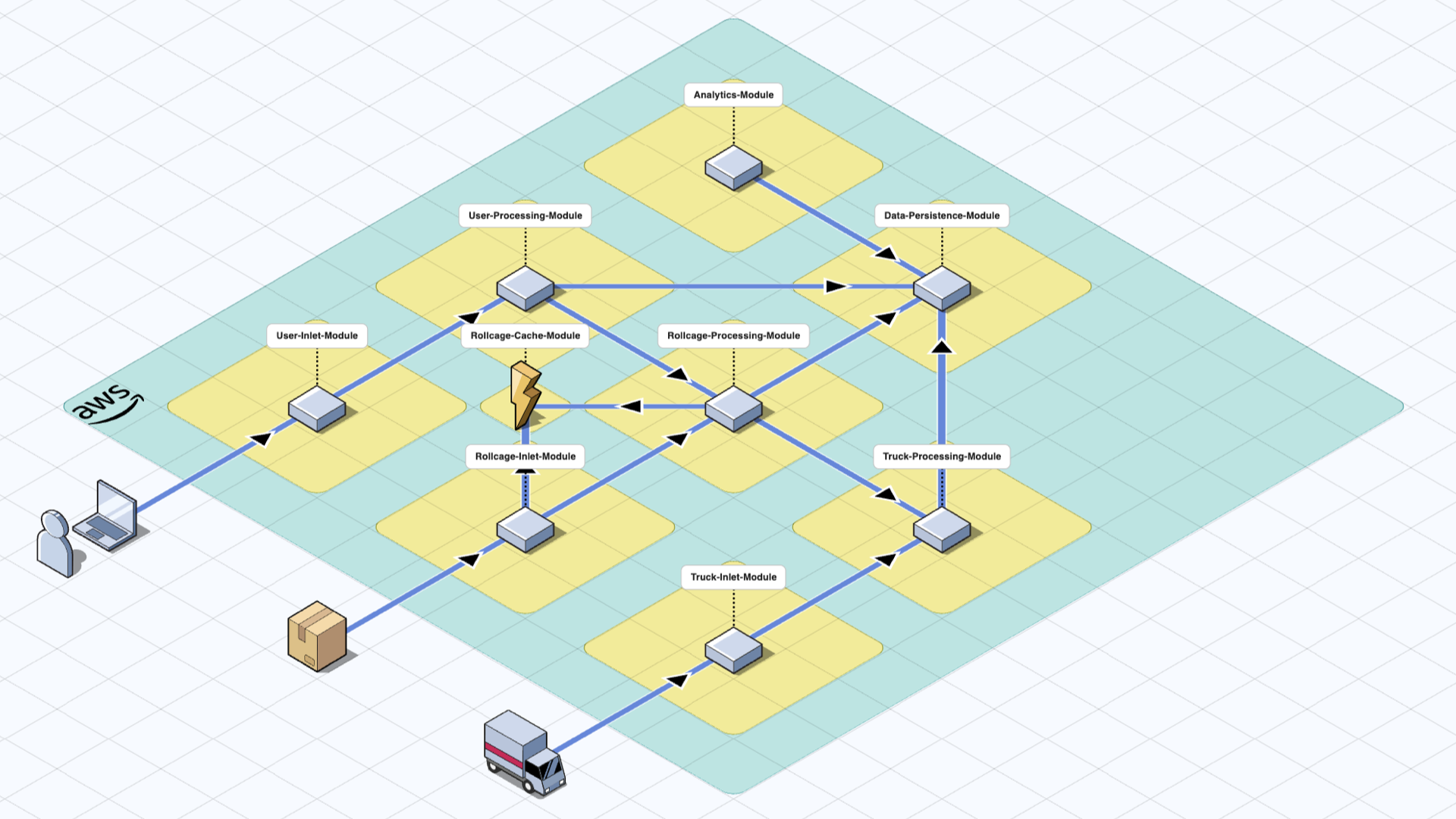
Serverless Modules
The serverless modules are stored in their respective Git repositories, where the final artifact is a library which contains the necessary infrastructure code for the nested AWS CDK Stack.
For isolation between modules, in most cases, we design our modules to consume and publish their data via AWS integration services like SNS, SQS, EventBridge or Kinesis.
Once development is complete and the module is ready for release, we create a TypeScript library using the AWS CDK infrastructure code. This library is versioned and stored in our package manager, ready for integration into the main CDK application. The main CDK application will then add the module as a dependency by referencing this library version.
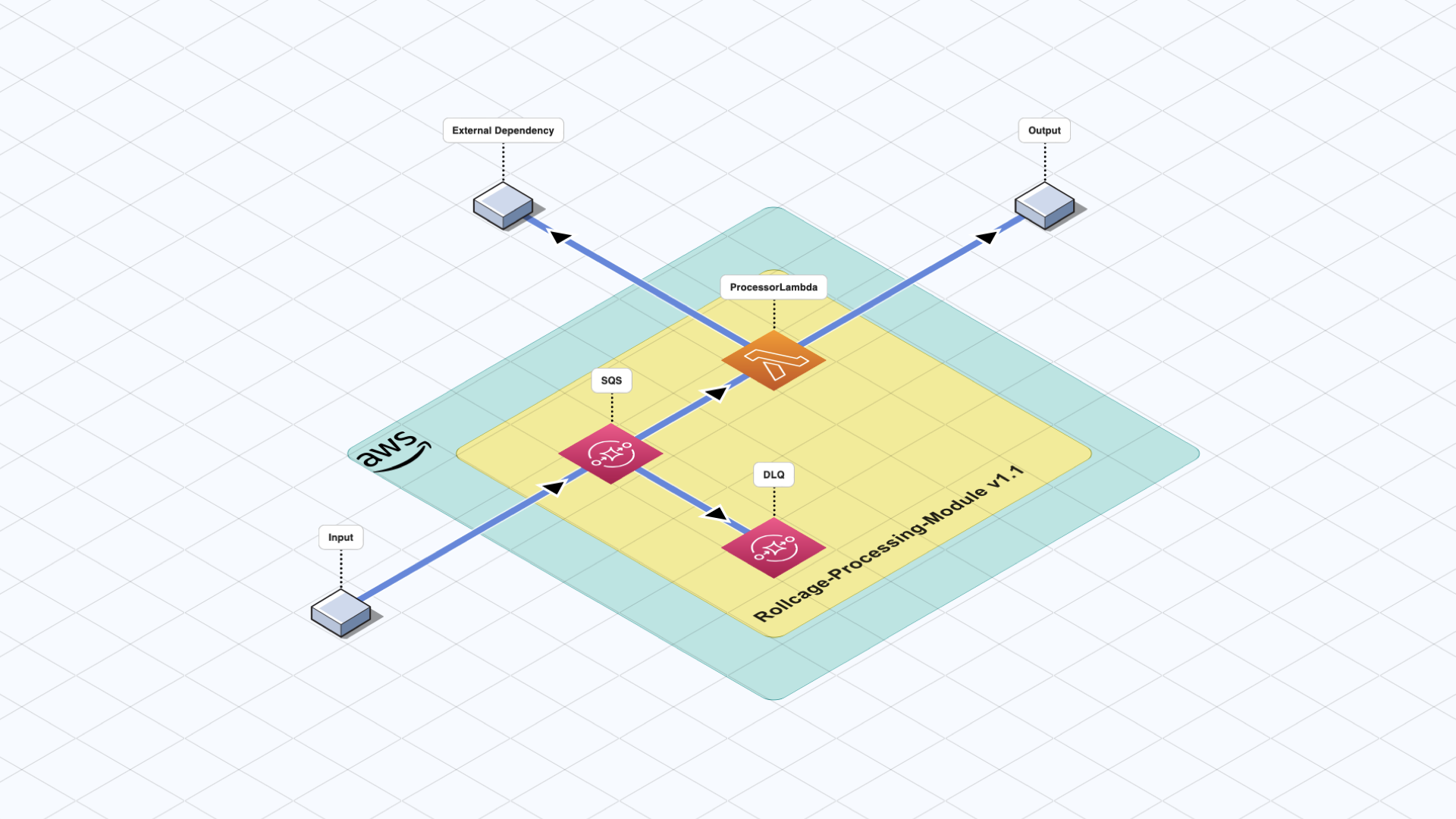
The main CDK application has dependencies on all the modules with versioning, manages the connections between these modules, and determines the data flow by connecting the necessary integration services between the modules. In some cases, key integration services or components like an EventBus on the EventBridge can be created by the main application and connect the modules to establish the producer/consumer relation.
Module connections also determine the order of deployment. Fortunately, we do not have think about it or manage it ourselves, and this is one of the core competencies of “Serverless Modular Monolith”s. AWS CDK manages these dependencies during the deployments and deploys the modules in the correct order. This aspect alone saves significant amount of time for complex systems.
Once the CDK app is successfully deployed, each module can work in isolation thanks to the integration services in between (SNS, SQS, EventBridge, Kinesis … etc.). From that point forward, the modules will scale up and down automatically, behaving similarly to microservices.
After the first deployment, AWS CDK will make comparisons to the existing application with all its modules and compare the state before making changes to the infrastructure and it is smart only to update the parts that we have updated. In most of the cases, this state transition is seamless and does not require manual planning. AWS CDK will create new resources and replace the old ones without interrupting the running services. As a rule of thumb, we should be careful about changes in data persistence, but this is topic too far detailed and needs to be discussed separately than this post.
As a recap, here are the list of best practices that we follow while building these so-called “Modules”:
- Single Responsibility: Each module has a single responsibility and is isolated from any other module.
- Isolation and Testing: Modules can be deployed individually for testing purposes, allowing extensive integration tests to validate behavior before they are plugged into the main application.
- Versioning: Each module is versioned so its development can progress independently of other modules.
- Scalability: Modules scale up and down depending on the hot-spots within the applications, thanks to their independence and connection through integration services.
- Cost Efficiency: We can tag each module to track individual costs and improve cost efficiency if necessary.
- Logical Boundaries: Modules have logical boundaries, which, combined with their single responsibility, make the overall system easy to reason with. This approach ensures a good developer experience and low cognitive load during development.
Distinction between Modules and Microservices
Modules and microservices differ on multiple aspects, but here are the key ones from my perspective:
- Deployment: Modules are deployed as nested CDK stacks within the main CDK application, while microservices are deployed as separate AWS CDK applications. Therefore, microservices require complex deployment orchestration and strategies. Developers are responsible for managing the dependencies between microservices.
- Versioning & Updates: Updates in microservices require careful coordination between services for breaking changes and additional testing is necessary on overall system level to make sure that the changes are compatible. The same is also true for modules, but the effort is much lower, because overall system is deployed as a single unit.
- Integration: Changes in bounded contexts are more complex to manage in microservices and getting them right requires a good understanding of the overall system. When bounded contexts are not right, we will be risking difficult challenges like “Distributed Transactions”.
Practical Benefits in Action
There are a number of practical benefits of using “Serverless Modular Monolith”. In the following list, I would like to summarize the ones that we use a lot:
- Smooth version migrations with backward compatibility
- Side-cars,
- A-B Testing.
Version migrations
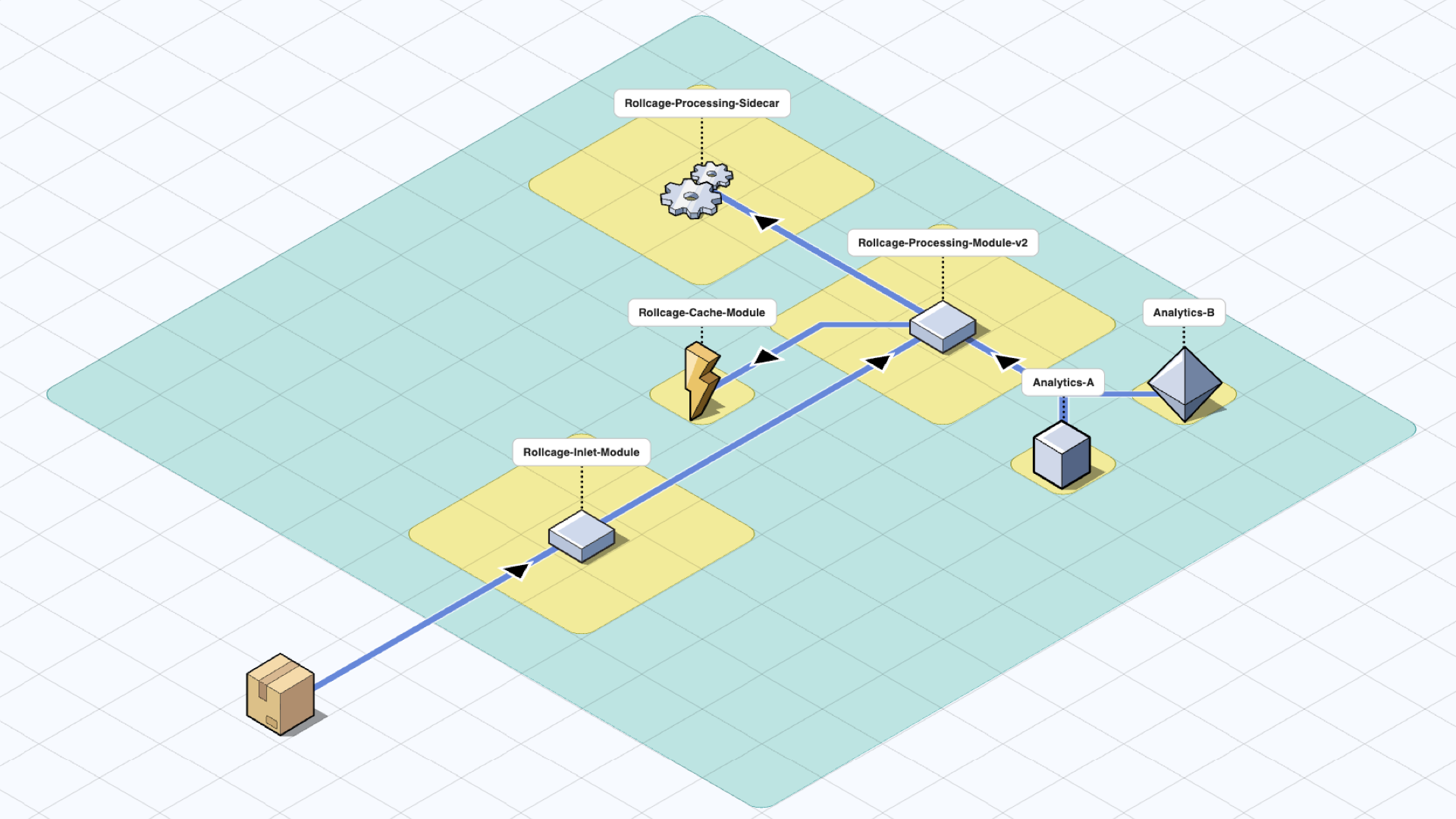
In this first scenario, let’s assume that we have been running the Rollcage-Processing-Module in v1 for some time and we are now ready to deploy v2. In the following figures, other modules are not shown for simplicity.
In a “Serverless Modular Monolith” architecture, we have the possibility to deploy two versions of the same module. There are multiple ways to achieve that, but here are the first two approaches that comes to mind:
- Make a name change in the library and deploy it like a new module along with the previous version. (Like Rollcage-Processing-Module-v2)
- Hide the new version functionality behind a feature flag and deploy another instance of the the same module with feature flag enabled.
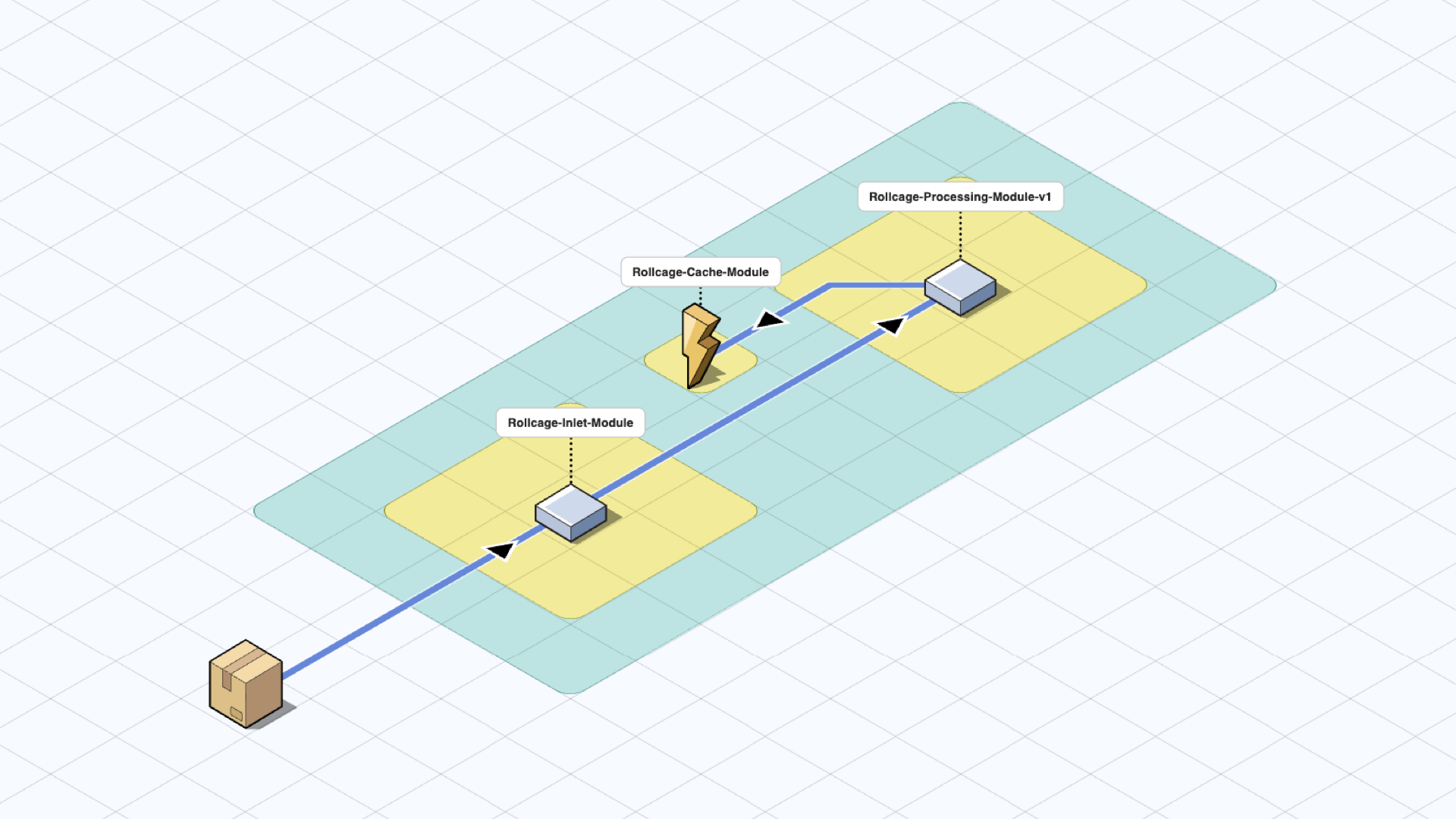
When we select one of the above approaches and deploy two versions, we can run them together until we are ready to phase out v1. Phase out criteria might depend on the situation. Some possible scenarios could be:
- Until the cache of the new version catches up with the old one.
- If this was an outlet module where other teams were dependent on your system, we can wait until all teams migrate to v2.
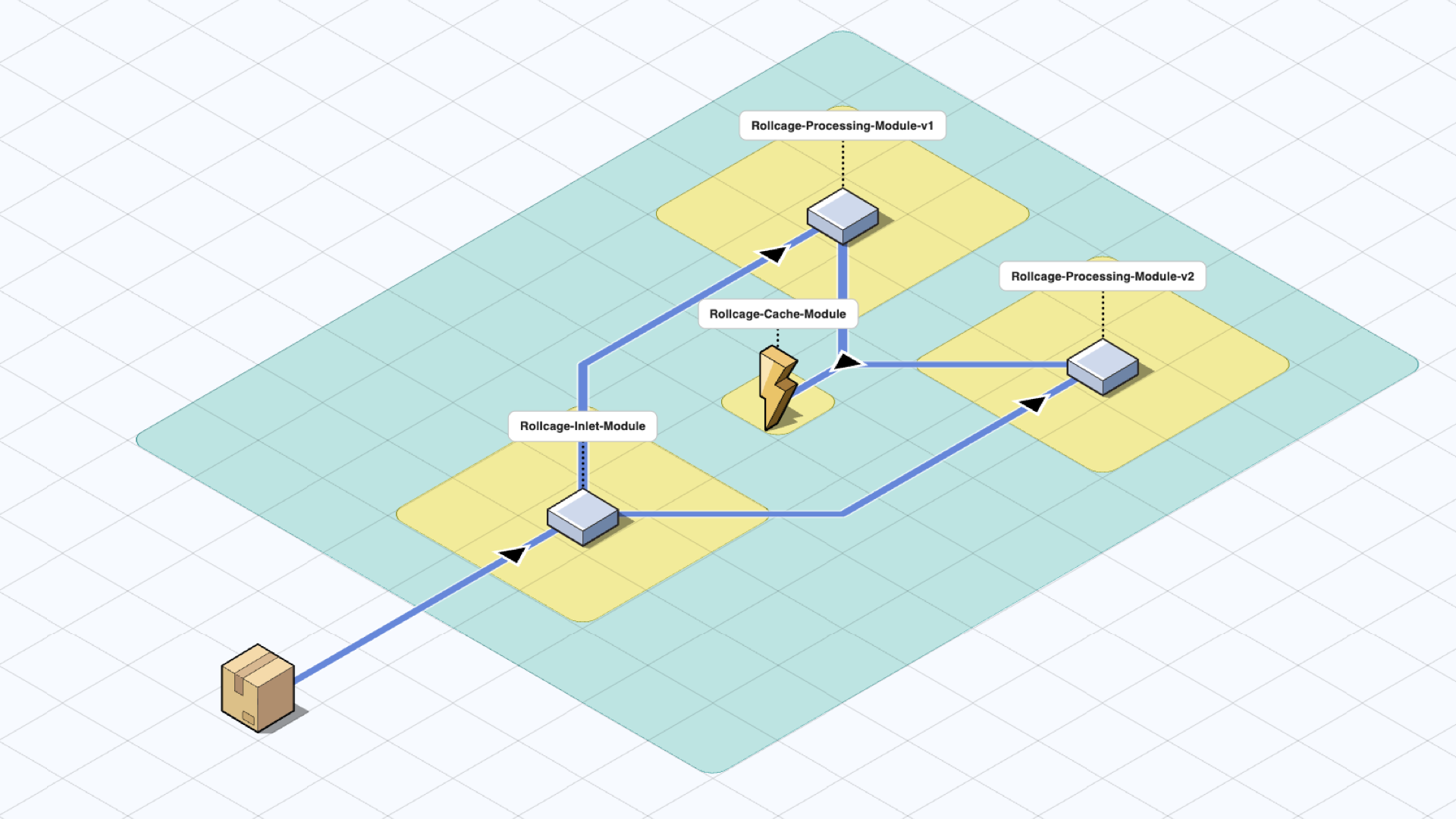
Once the phase out requirements are met, we can decommission v1 and continue our development through v2.
This approach ensures backward compatibility during the entire process and allows stakeholders to catch up at their own pace using communicated sunset dates for older versions.
Side-cars
Another possibility is to add a side-car module. This pattern is named “Side-car” because it resembles a side-car attached to a motorcycle. In this pattern, the side-car is attached to a parent application and provides supporting features for the application. This allows us to decompose some features into a separate module. A sample use case could be as follows:
A module for processing incoming events is required to store the last 60 days of events in storage. In this use case, the persistence responsibility can be offloaded to a side car which keeps the business logic in processing module simple.
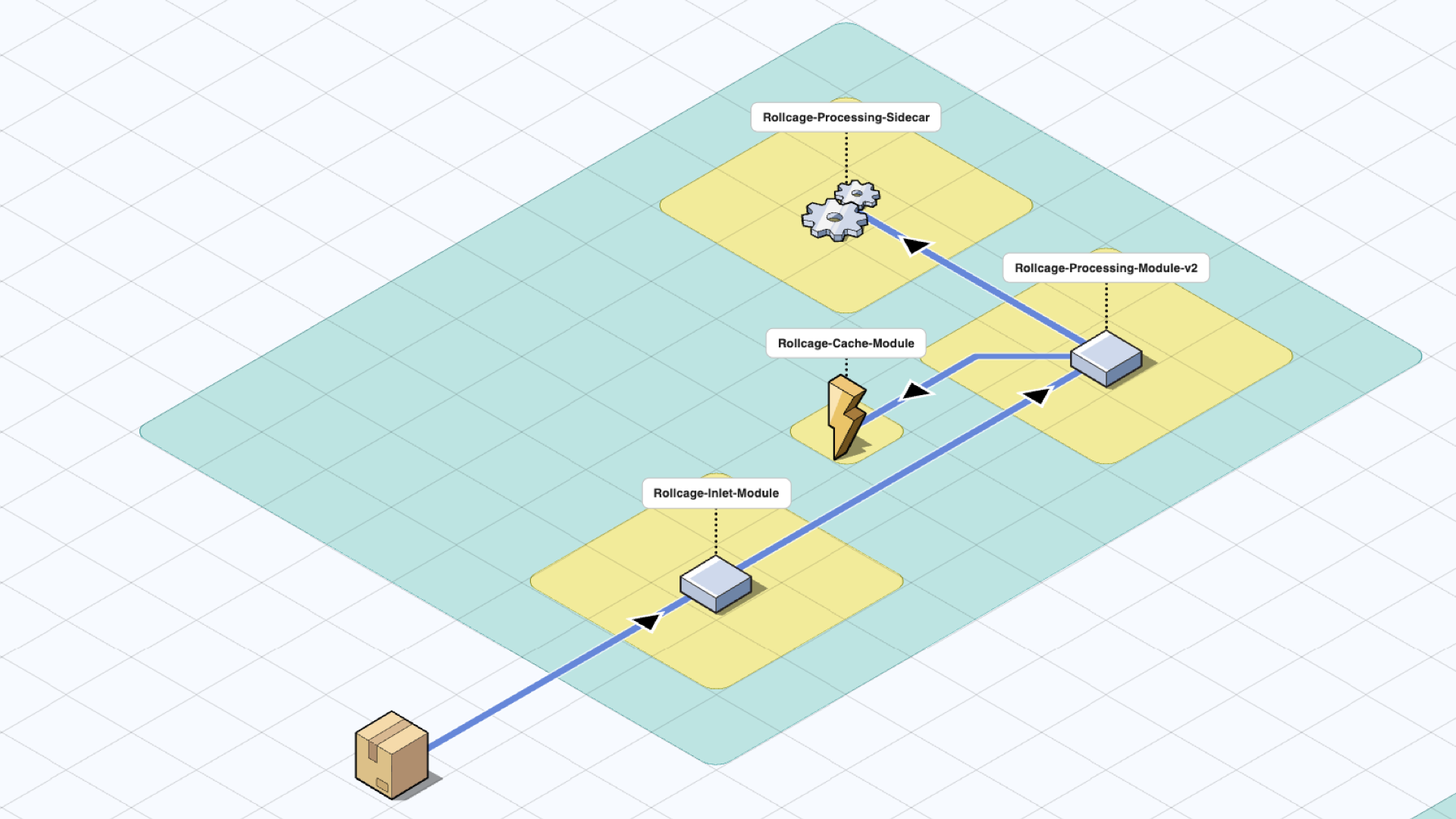
A-B Testing
The “Serverless Modular Monolith” architecture also makes A-B testing straightforward. Let’s say that you want to add analytics and see two possible ways to extract data from the system, but you do not know which one would work better. This is an exploration case where we don’t know the outcome of the research yet, and the approach includes a “Sacrificial Architecture.” It is easy to connect both and see which one performs better. Simply sacrifice the other once we are happy with the results.
Evolving Towards Microservices
As our applications grow, there’s always the potential to evolve them into fully distributed microservices. By carefully managing the bounded contexts within our applications, we can split a modular monolithic system into multiple microservices, each with its own AWS account. We can also assign responsibility to multiple teams and manage complexity effectively.
The ability to evolve from a modular monolith to microservices without a complete architectural overhaul is one of the key benefits of the “Serverless Modular Monolith”. This approach allows us to find the balance between stability and flexibility so that we can continue to adapt and grow.
Recap and Conclusions
Throughout the series, we’ve explored the advantages of the “Serverless Modular Monolith” and how it can address the evolving needs of modern applications. By balancing simplicity, scalability, and adaptability, this architecture enables us to start small, evolve incrementally, and manage complexity effectively.
We have covered the following benefits of the “Serverless Modular Monolith”:
Modular design mitigates common challenges and opens possibility to evolve towards microservices without complete overhaul of the system:
- Less cognitive load for developers and easy to reason with the overall system.
- Loose coupling, high functional cohesion
AWS CDK simplifies the application deployment to a single command:
cdk deployand handles complex deployment orchestration, especially during early development phase.- We do not need to think about deployment strategies right from the start.
- Only the first deployment is a monolith, after that in each deployment AWS CDK is smart enough to only reflect the changes or add the new components.
The architecture style provides a balance between exploration and exploitation.
- If we need something fast, we can reuse what we have built so far.
- If we need to experiment, it is easy to plug in new features to the application.
If you don’t have a plan for how your system will evolve, it won’t survive the test of time. Starting with the “Serverless Modular Monolith” gives you a solid and flexible foundation that supports growth and evolution for your systems.
This blueprint has helped us at PostNL, and I hope it can serve as inspiration for you as well. If this architectural evolution is interesting for you, I encourage you to explore the concept “Evolutionary Architectures”.
I hope you enjoyed this series and thank you for reading so far. This blog post series is also available as a presentation and if this is an interesting topic for you, please reach out to me from a platform of your choice. You can see possibilities from my About page.
Happy coding and see you next time!
References
- Anti-pattern: Big Ball of Mud
- https://pretius.com/blog/modular-software-architecture/
- https://www.thoughtworks.com/en-us/insights/blog/microservices/modular-monolith-better-way-build-software
- https://medium.com/design-microservices-architecture-with-patterns/microservices-killer-modular-monolithic-architecture-ac83814f6862
- https://serverlessfirst.com/emails/why-monolithic-deployments-make-sense-for-small-serverless-teams/
- PostNL facts and some numbers about parcel delivery